Introduction
The Builder Pattern is a creational design pattern that’s used to encapsulate the construction logic for an object. It is often used when the construction process of an object is complex. The patterns is well suited for constructing different representations of the same class.
Purpose
- Separate the construction of a complex object from its representation so that the same construction process can create different representations.
- A common software creational design pattern that’s used to encapsulate the construction logic for an object.
Design Pattern Diagram
The Builder Pattern is comprised of four components: a builder interface, a concrete builder, a director and a product.
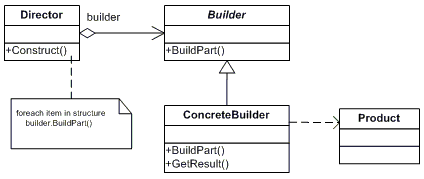
Builderdefines a template for the steps to construct the product. Specifies an abstract interface for creating parts of a Product object.Concrete Builderimplements the builder interface and provides an interface for getting the product. Constructs and assembles parts of the product by implementing the Builder interface defines and keeps track of the representation it creates provides an interface for retrieving the product.ConcreteBuilderbuilds the product’s internal representation and defines the process by which it’s assembled includes classes that define the constituent parts, including interfaces for assembling the parts into the final result.Directorconstructs the object through the builder interface.Productis the main object that’s constructed. Represents the complex object under construction.
Implementation
The Builder pattern separates the construction of a complex object from its representation so that the same construction process can create different representations. This pattern is used by mail service to construct children’s mails to Santa Claus.
Note that there can be variation in the content of the children’s emails, but the
construction process is the same. In the example, the service supports JSON
and XML.
The messages typically consist of body and format. They can be transmitted via different protocol. In order to do that their body should be encoded in the right format.
// Message is the Product object in Builder Design Pattern
type Message struct {
// Message Body
Body []byte
// Message Format
Format string
}
Every message body should consist the recipient and text. Therefore, the Builder
interface provides a functions to set these attributes. The Message function
is responsible for constructing the actual message in the right format.
// MessageBuilder is the inteface that every concrete implementation
// should obey
type MessageBuilder interface {
// Set the message's recipient
SetRecipient(recipient string)
// Set the message's text
SetText(text string)
// Returns the built Message
Message() (*Message, error)
}
The JSONMessageBuilder is a concrete implementation of the MessageBuilder
interface. It uses json package to
encode the message.
// JSON Message Builder is concrete builder
type JSONMessageBuilder struct {
messageRecipient string
messageText string
}
func (b *JSONMessageBuilder) SetRecipient(recipient string) {
b.messageRecipient = recipient
}
func (b *JSONMessageBuilder) SetText(text string) {
b.messageText = text
}
func (b *JSONMessageBuilder) Message() (*Message, error) {
m := make(map[string]string)
m["recipient"] = b.messageRecipient
m["message"] = b.messageText
data, err := json.Marshal(m)
if err != nil {
return nil, err
}
return &Message{Body: data, Format: "JSON"}, nil
}
The XMLMessageBuilder is a concrete implementation of the MessageBuilder
interface. It uses xml package to encode
the message.
// XML Message Builder is concrete builder
type XMLMessageBuilder struct {
messageRecipient string
messageText string
}
func (b *XMLMessageBuilder) SetRecipient(recipient string) {
b.messageRecipient = recipient
}
func (b *XMLMessageBuilder) SetText(text string) {
b.messageText = text
}
func (b *XMLMessageBuilder) Message() (*Message, error) {
type XMLMessage struct {
Recipient string `xml:"recipient"`
Text string `xml:"body"`
}
m := XMLMessage{
Recipient: b.messageRecipient,
Text: b.messageText,
}
data, err := xml.Marshal(m)
if err != nil {
return nil, err
}
return &Message{Body: data, Format: "XML"}, nil
}
The sender object decides what should be the content of the email and its recipient (ex. Santa Claus).
// Sender is the Director in Builder Design Pattern
type Sender struct{}
// Build a concrete message via MessageBuilder
func (s *Sender) BuildMessage(builder MessageBuilder) (*Message, error) {
builder.SetRecipient("Santa Claus")
builder.SetText("I have tried to be good all year and hope that you and your reindeers will be able to deliver me a nice present.")
return builder.Message()
}
We should use the designed architecture to build XML and JSON messages in the following way:
sender := &messenger.Sender{}
jsonMsg, err := sender.BuildMessage(&messenger.JSONMessageBuilder{})
if err != nil {
panic(err)
}
fmt.Println(string(jsonMsg.Body))
xmlMsg, err := sender.BuildMessage(&messenger.XMLMessageBuilder{})
if err != nil {
panic(err)
}
fmt.Println(string(xmlMsg.Body))
Verdict
As you can see, the true strength of the Builder Pattern is that it lets you break up the construction of a complex object. Not only that, it also allows you to hide the construction process from the consumer, thus allowing for additional representations of the product to be added with ease. The pattern also encourages separation of concerns and promotes application extensibility